
MySQL
Mysql基础(再来一次)
概念
数据库(DataBase):存储数据的仓库,数据是有组织的进行存储
数据库管理系统(DataSource Manager ):操纵和管理数据库的大型软件
SQL(structed Query Language):操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准
市场常用数据库管理系统
(·MySQL爆火的原因:白嫖的就是香)
数据库类型
关系型数据库
概念:建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
特点:
1.使用表存储数据,格式统一,便于维护
2.使用sQL语言操作,标准统一,使用方便
SQL
SQL通用语法
1.SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 注释:
单行注释:–注释内容或#注释内容(MySQL特有)
多行注释:/* 注释内容 */
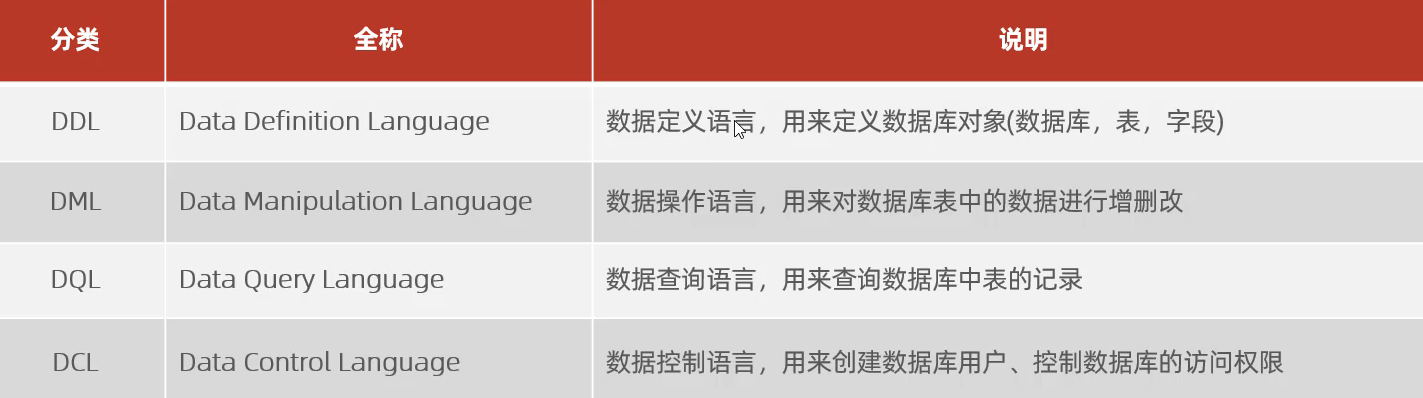
SQL语句分类
DDL-数据库操作
查询
查询所有数据库
```sql
show databases;1
2
3
4
5
- 查询当前所使用数据库
- ```sql
select database();
创建
- ```sql
create database [if not exists] 数据库名 [default charset 字符集] [collate 排序规则]1
2
3
4
5
- 删除
- ```sql
drop database[if exists] 数据库名
- ```sql
使用
- ```sql
use 数据库名1
2
3
4
5
6
7
#### DDL-表操作-查询
查询当前数据库所有表
```sql
show tables;
- ```sql
查询表结构
1 | DESC 表名; |
查询指定表的建表语句
1 | show create table 表名; |
DDL-表操作-创建
1 | create table 表名{ |
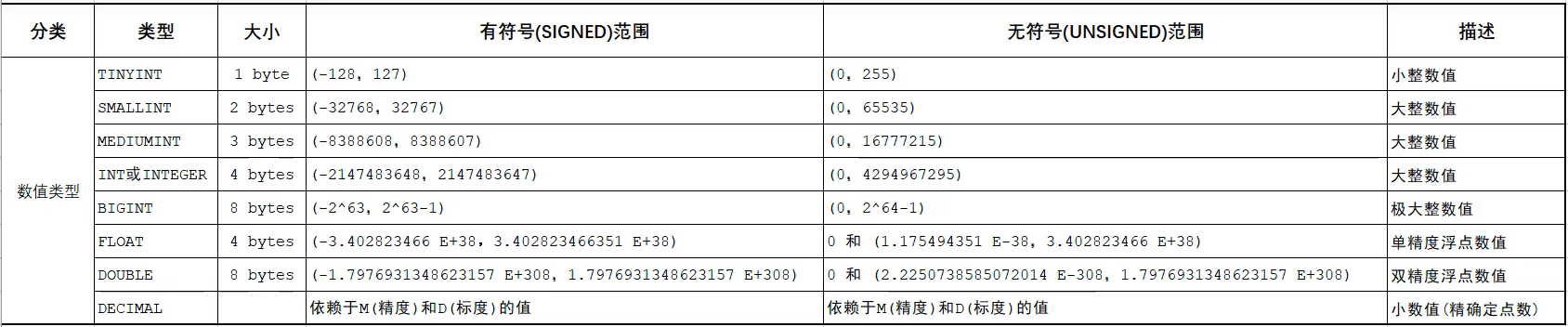
DDL-表操作-数据类型
精度 标度:
精度就是将该小数的整数部分和小数部分的位数加在一起的位数。
标度就是小数的位数
例如:123.45 精度就是5 标数就是2
正确的使用数据类型: 例如 ,当我们的字段为年龄时,我们就不必要将其数据类型设置为INT,而是要设置为TINYINT,且年龄这个字段不为负数,所以在定义时SQL语句时这样的
1 | age TINYINT UNSIGNED |
例如,在统计成绩时,我们一般精确到小数点后两位,所以我们就可以在设置的时候设置为 DOUBLE(5,2) ,且分数不会为负数,所以在定义时的SQL语句是这样的
1 | score DOUBLE(5,2) UNSGINED |
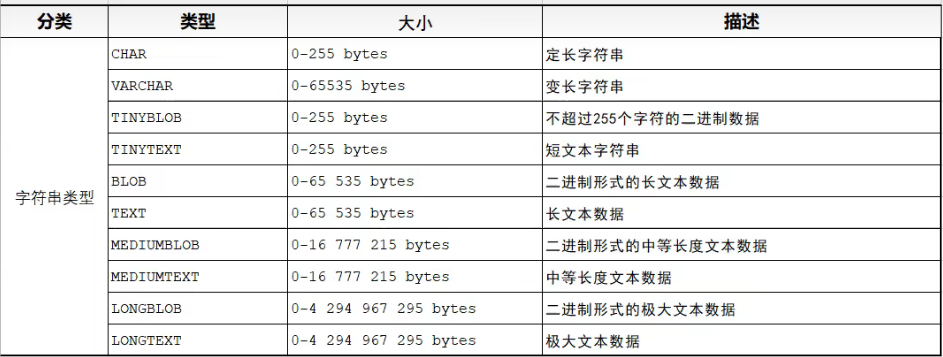
Char的性能要比varchar要好,但是varchar的优点是长度可变
要去合适的去使用字符串类型:例如 ,当我们存储用户名时,一般要求用户名长度不低于某个值不高于某个值,但是没有固定的长度,这时就要用
varchar(最高值),当我们要储存性别这个数据时,一般性别只有男或女这两个选择,且这两个值的字符长度都为1,有固定长度,所以这时我们就要用
char(1)

DDL-表操作-修改
添加字段
1 | alter table 表名 add 字段名 类型(长度) |
修改数据类型
1 | alter table 表名 modify 字段名 新数据类型(长度) |
修改字段名和字段类型
1 | alter table 表名 change 旧字段名 新字段名 类型(长度) |
删除字段
1 | alter table 表名 drop 字段名 |
修改表名
1 | alter table 表名 rename to 新表名 |
DDL-表操作-删除
删除表
1 | drop table [if exists] 表名; |
删除表并重新创建该表
1 | truncate table 表名; |
DML-添加数据
给指定字段添加数据
1 | insert into 表名(字段1 ,字段2,……) values(值1,值2,……); |
给全部字段添加数据
1 | insert into 表名 values(值1,值2,……); |
批量添加数据
1 | insert into 表名(字段名1,字段名2,……) values(值1,值2,……),(值1,值2,……),(值1,值2,……); |
DML-修改数据
1 | update 表名 set 字段名=1,字段名=2,…… where (条件) |
DML-删除数据
1 | delete from 表名 where[条件] |
DQL-语法
1 | select 要查询的字段名 |
DQL基本语法
1 | #查询多个字段 |
DQL-条件查询
1 | select 字段列表 from 表名 where 条件列表 |
条件

DQL-聚合函数
将一列数据作为一个整体进行纵向计算
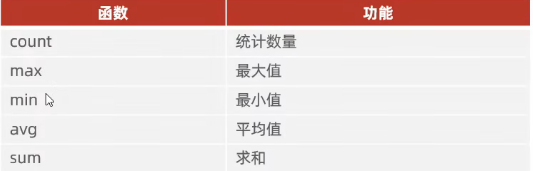
语法
1 | select 聚合函数(字段列表) from 表名 |
注意:某行的某字段为null时聚合函数计算该列时,不会将该行的该字段计算其中
DQL-分组函数
语法
1 | select 字段列表 from 表名 where 查询条件 group by 分组字段名 [having 分组后过滤条件]; |
where和having的区别
- 执行时机不同: where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同: where不能对聚合函数进行判断,而having可以。
注意
执行顺序: where >聚合函数>having 。
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
DQL-排序查询
1 | select 字段列表 from 表名 order by 字段 排序方式1 , 字段2 排序方式2; |
排序方式
ASC:升序(默认)
DESC:降序
注意:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
DQL-分页查询
1 | select 字段列表 from 表名 where 条件 limit 页号,每页大小 |
函数
字符串函数
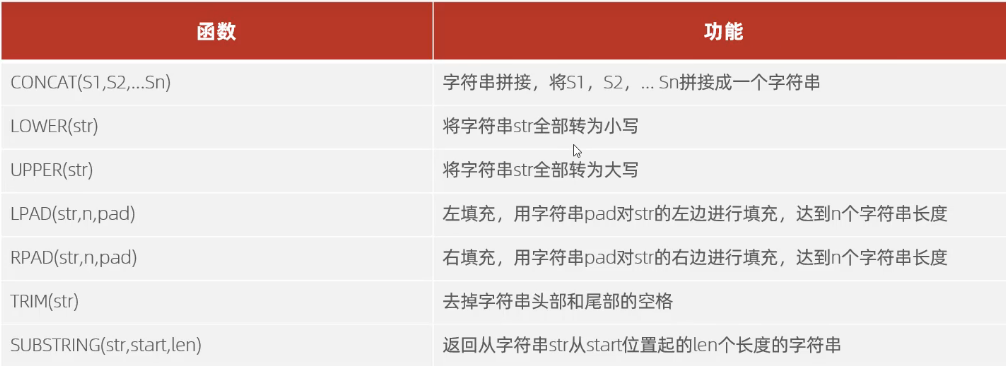
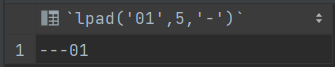
左填充和右填充的区别实际上和加前缀和后缀的是一样的
1 | select lpad('01',5,'-'); |
1 | select rpad('01',5,'-'); |

倘若我又一个员工表,这时员工ID需要填充到五位,不足五位的需要0补齐
1 | update employee set enum=leap(enum,5,'0'); |
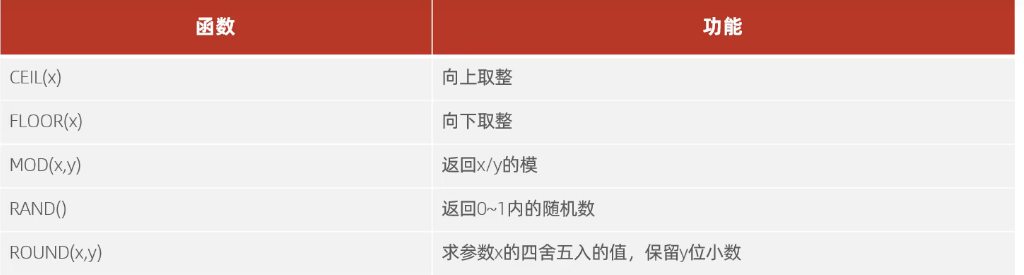
数值函数
日期函数
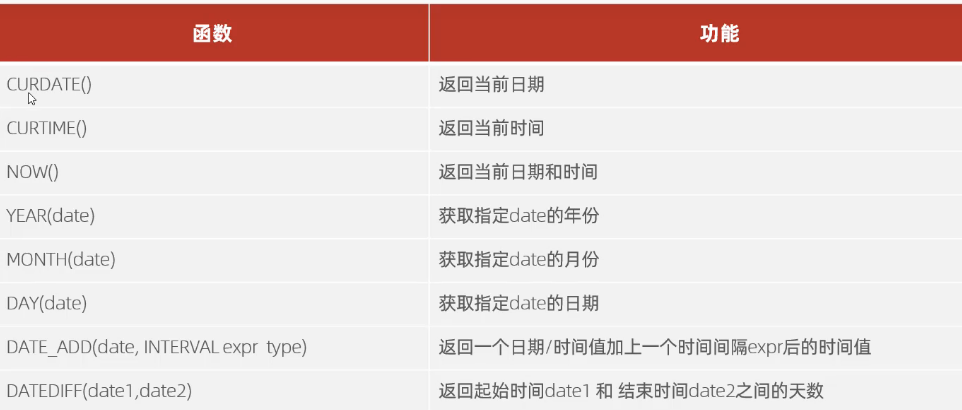
对于date_add函数的使用
1 | select date_add(now(),INTERVAL 70 day ); |



1 | select datediff(curdate(),'2001-11-29'); |


流程函数
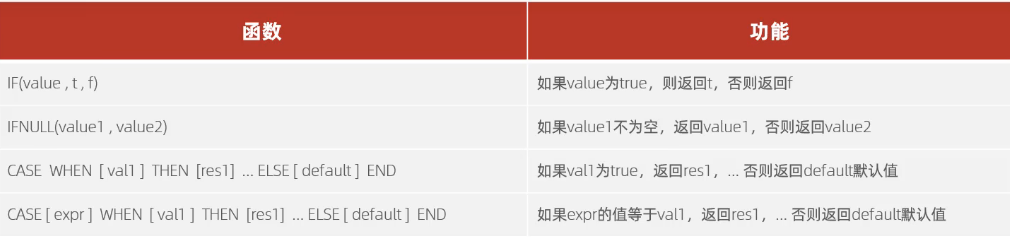
1 | select if(true,1,2); #执行结果:1 |
1 | select ename, case when address in ('北京','上海','深圳','广州') then '一线城市' |
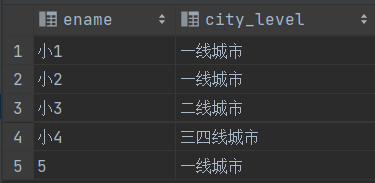
约束
- 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确、有效性和完整性。

多表查询
多表关系
一对多
一对多:在多的一方设置外键,关联一的一方的主键
多对多
多对多:建立中间表,中间表包含两个外键,关联两张表的主键
一对一
一对一:用于表结构拆分,在其中任何一方设置外键(UNIQUE),关联另一方的主键
多表查询分类
连接查询
内连接:相当于查询A、B交集部分数据
隐式内连接
1 | select 字段列表 from 表1,表2 where 条件; |
显式内连接
1 | select 字段列表 from 表1 join 表2 on 连接条件; |
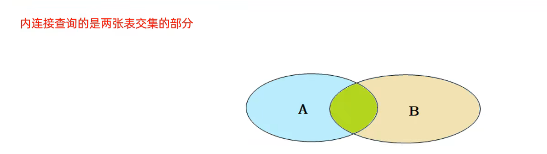
外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据(即使on条件中表1对应条件的字段为空则也要保存)
1 | select 字段列表 from 表1 leaf join 表2 on 条件; |
- 右外连接:查询右表所有数据,以及两张表交集部分数据(即使on条件中表2对应的条件不存在则也要保存)
1 | select 字段列表 from 表2 right join 表2 on 条件; |
自连接:当前表与自身的连接查询,自连接必须使用表别名
1 | select 字段列表 from 表名 别名A join 表A 别名B ON 条件; |
联合查询-union,union all
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
1 | select 字段列表 from 表A , |
例如:我们要想将 薪水大于5000的员工的结果与年龄大于50的结果合并 则可以
1 | select * from emp where salary>5000 |
对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
union all会将全部的数据直接合并在一起,union会对合并之后的数据去重。
子查询
概念:SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
子查询外部的语句可以是INSERT / UPDATE/DELETE/SELECT的任何一个。
根据子查询结果不同,分为:
标量子查询(子查询结果为单个值)
列子查询(子查询结果为一列)
行子查询(子查询结果为一行)
表子查询(子查询结果为多行多列)
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询成为标量子查询。
常用的操作符:=、<>、>、>=、<、<=
例如:要展示销售部的所有员工
首先第一点我们要找出销售部的ID号
1 | select id from dept where dept.name='销售部' |
第二点我们要找到如何列出某部的所有员工
1 | select name from emp where dept_id=xxx; |
组合起来就是我们要查询的语句了
1 | select name from emp where dept_id=(select id from dept where dept.name='销售部'); |
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用的操作符:IN 、NOT IN 、ANY . SOME 、 ALL
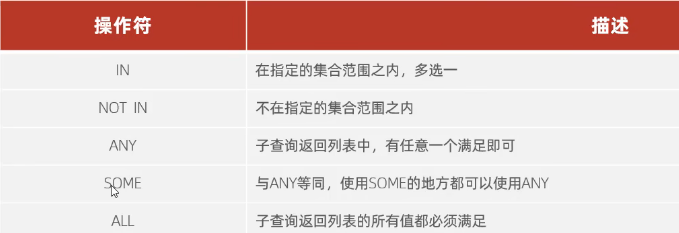
倘若要查找 公司中 比财务部所有人工资都高的员工的个人信息(比所有人都高,比最高的高)
1 | #all |
倘若要查找比研发部其中一人工资高的个人信息(比一个人高就行,比最低的高就行)
1 | #any |
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:= 、<>、IN 、NOT IN
查询与张无忌的薪资和上司相同的其他员工
1 | select * from emp e1 where (managerid,salary)=(select managerid,salary from emp where name='张无忌'); |
张无忌的信息查询出来为一行
所以当查询的时候,需要两个managerid和salary一起作为条件查询

表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
根据子查询位置不同,分为: Where之后、From之后、select之后
事务
事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务操作
1 | select @@autocommit; #查看是否自动提交 |
事务的四大特性
原子性(Atomicity)︰事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
隔离性(Ilsolation)∶数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务问题

事务的隔离级别
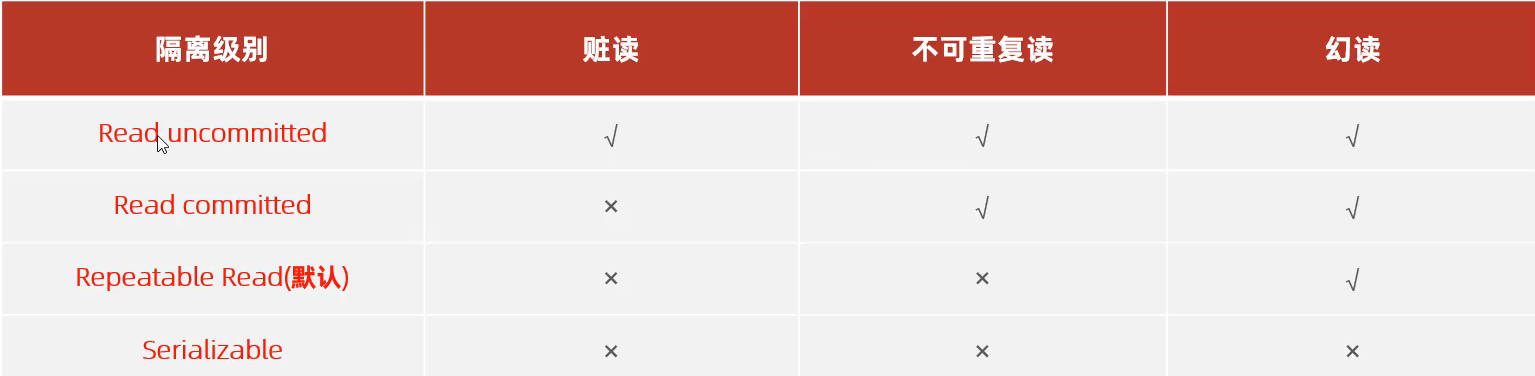
查看事务的隔离级别
1 | select @@TRANSACTION_ISOLATION; |
设置事务隔离级别
1 | set [session|global] transaction isolation level [repeatable read|Read uncommited|Read committed|Repeatable Read|Serialzable] ; |



