
Dubbo
Dubbo
分布式系统
为了达成大型互联网项目架构的目标,分布式系统出现了
大型互联网项目架构目标
衡量网站的性能指标
- 响应时间:指执行一个请求从开始到收到相应所花费的总体时间
- 并发数:指系统同时能够处理的请求数量
- 并发连接数:指的时客户端向服务器发送请求,并建立TCP连接,每秒服务器连接的总TCP数量
- 请求数:也称为QPS(Query per Second)指每秒多少请求
- 并发数:单位时间内有多少用户
- 吞吐量:单位时间内系统能够处理的请求数量
- QPS:Query Per Second 每秒查询数
- TPS: Transcations Per Second 每秒事务数
- 一个事务是指一个客户机向服务器发送请求然后服务器作出反应的过程,客户机在发送请求时开始计时,收到服务器响应后结束计时,从此来计算使用的时间和完成的事务数
- QPS >= 并发连接数 >=TPS
- 高性能:提供快速的访问体验
- 高可用:网站服务一直可以正常访问
- 可伸缩:通过硬件增加/减少,提高/降低处理能力
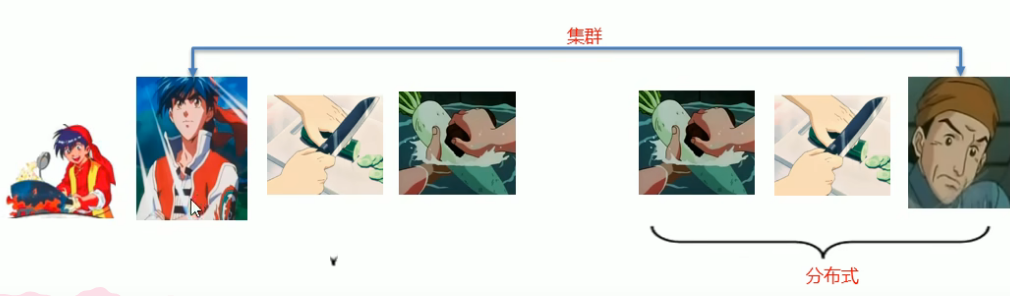
集群和分布式
- 集群:很多“人”一起,干一样的事
- 分布式:很多“人”一起,干不一样的事。这些不一样的事,合起来是一件大事
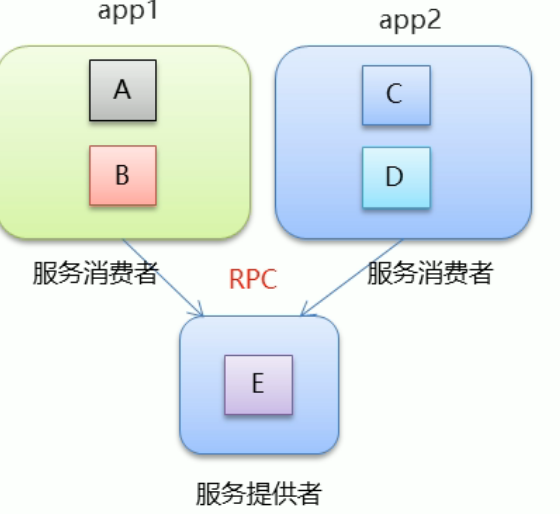
在分布式架构,服务的消费者和服务的提供者之间的通信由RPC来实现
- 分布式架构是指在垂直架构的基础上,将公共业务模块抽离出来,作为独立的服务,供其他调用者消费,以实现服务的共享和重用
- RPC:Remote Procedure Call 远程过程调用,有非常多的协议和技术来实现RPC过程,比附HTTP REST风格,Java RMI规范、WebService SOAP协议、Hession等等
概述
- Dubbo是阿里巴巴公司开源的一个高性能、轻量级的JavaRPC框架
- 致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案
- 官网:http://dubbo.apache.org
Dubbo架构
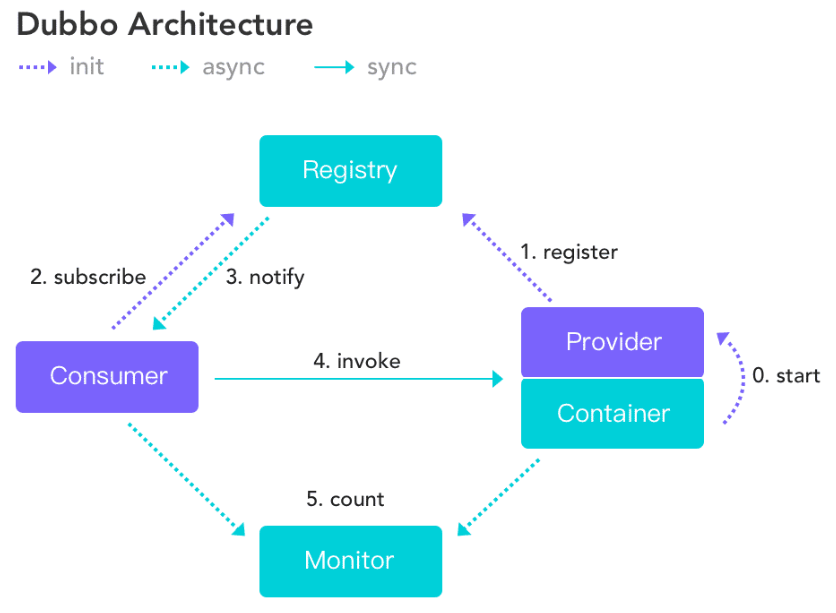
Dubbo的特性
地址缓存
- 当zookeeper突然宕机时,我们服务之间的调用是否还会继续调用?
- 会,当服务之间在初次调用时,会将zookeeper中的服务提供方的地址缓存到本地,以后在调用则不会访问注册中心
- 当服务提供者地址发生变化时,注册中心会通知服务消费者
超时和重试
超时
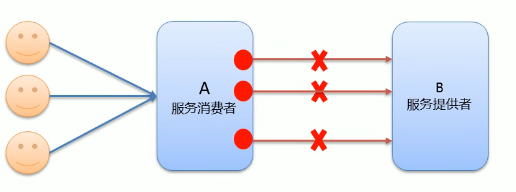
- 服务消费者在调用服务提供者的时候发生了阻塞,登台的情况,这个时候这个服务的消费者会一直等待下去
- 在某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆积,势必会造成雪崩
- dubbo利用超时机制来解决这个问题,设置一个超时时间,在这个时间段内,无法完成服务访问,则自动断开链接
- 在服务提供方的@Service(Dubbo)的注解中添加属性timeout=x000 reties=2,指的是如果x秒后链接不成功,则自动断开链接
为什么要在服务提供方的@Service添加属性而不是在服务消费方@Reference中添加属性呢?
因为在实际开发中,服务的提供方和服务的请求方并非同一人员开发,但服务的提供方往往要对数据库中的数据进行相关操作,服务方会预估大概的操作时长,依据这个操作时长来给出对应的超时时长(@Reference中的属性会覆盖@Service中的属性)
重试
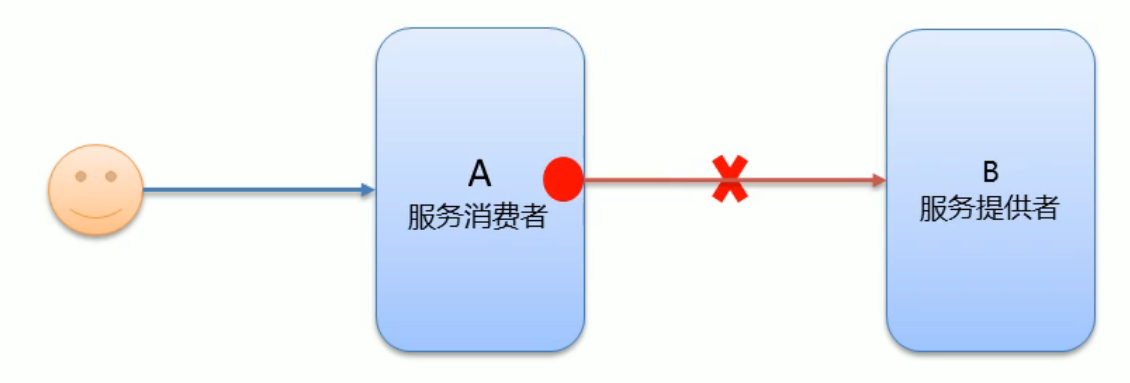
在服务消费者去请求链接服务提供者时,如果超过了超时时长,则会自动断开链接,但我们的请求并非每次都能调用成功,例如出现网络抖动时,我们仍然需要断线重连,所以Dubbo为我们提供了重试机制来避免类似事情的发生
- 通过reties属性来设置重试次数,默认为两次
多版本
在进行服务调用时,我们服务提供者会版本更新,当更新时会让一部分用户先使用新功能,用户反映没有问题时,再将所有用户迁移到新功能这就是灰度发布
如何实现灰度发布?
在服务消费者的@Reference注解中添加属性version=”v1.0(v2.0)”即可实现服务的灰色发布
负载均衡
服务消费者在请求连接服务提供者时,有多个服务提供者,那么服务消费者又以什么策略去请求哪个服务提供者呢?为实现这个问题Dubbo给出了方案:负载均衡
Dubbo的负载均衡有4种策略
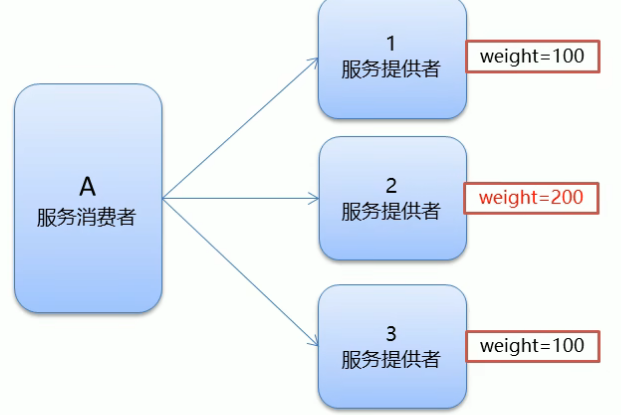
- Random:按权重随机,默认值。按权重设置随机概率,根据下图,服务提供者2的权重比为200/(200+100+100)=50%,所以请求连接到他的概率就为50%
- RoundRobin:按权重轮询,倘若三个服务提供者的权重分别为provider1: 2 。provider2:3.。provider3:5,依据权重比2:3:5,说明当轮询10次时,一定会出现provider1被调用2次,provider2被调用3次,provider3被调用5次
- LeastActive:最少活跃调用数,相同活跃数的随机。这里需要解释一下,当我们的服务提供者在提供服务时(能同时提供给不止一个消费者),服务的记数就会加一,相当于服务的调用数+1,服务结束后,再将服务调用数减一。当providerA开始为一个consumer提供服务时他的权重为1,同时providerB也开始为一个consumer提供服务他的权重也为1,这时providerB的处理速度比较快,服务提供完毕,providerB 的权重就为0,而这时providerA 还在继续刚才的服务提供,所以这时它的权重就为1, 这时 又有consumer请求服务, 根据LeastActive策略: providerA的权重>providerB的权重,所以providerB将会进行服务
ConsistentHashLoadBalance: 一致性Hash算法 ,还没搞懂
集群容错
集群容错模式
- Failover Cluster :失败重试,默认值 2。当出现失败,重试其他服务器,默认重试两次,使用retries配置,一般用于读操作
- Failfast Cluster :快速失败,只发起一次调用,失败立即报错。通常用于写操作
- Failsafe Cluster: 失败安全,出现异常时,直接忽略,返回一个空结果
- Failback Cluster: 失败自动恢复,后台记录失败请求,定时重发
- Forking Cluster: 并行调用多个服务器,只要一个成功即返回
- Broadcast Cluster:广播调用所有提供者,逐个调用,任意一台报错则不报错
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 MyBlog!



